
Everyday Data Science
"Young men should prove theorems, old men should write books."
- G.H. Hardy
Why I wrote a book?
During my graduate studies, I have been enthralled with how books often stay relevant and how quickly papers sink into obscurity. I wanted to write something that had value and durability. Why a book? Because books can last.
I am not old, but I wanted to take a break from theorem proving to write something light-hearted and decidedly non-academic.
Why this book?
My background is in mathematics, theoretical computer science, and machine learning. However, I got started down this path because of my love for data. Data can tell some pretty incredible stories, but it also can be extremely misleading. There are scores of introductory books about data science that start with Aggregation and finish with $z \sim N(0,1)$. They are designed for a technical audience and are often SO boring.
Don't get me wrong, I love these books. I helped with the recently released 2nd edition of Kevin Murphy's famed Machine Learning a Probabilistic Perspective. But I wanted my book to be more inspiration and less perspiration.
Who is it for?
This book is for people as untechnical as my Mom or as technical as my Applied Scientist friends working in big tech. The book is a nice, fun, and inspirational collection of stories.
These stories about data should get you thinking about your own life. I hope you ask if there are ways you can collect interesting data and learn something about yourself.
So what's in the book?

It is 114 pages long with 8 chapters. The chapters cover a wide range of fun data topics like how to use language models (and word vectors) to improve your resume, or how a man used statistics to qualify for the Olympics. As a fun warm up, chapter 2 shows how to use A/B testing to make the perfect glass of lemonade.
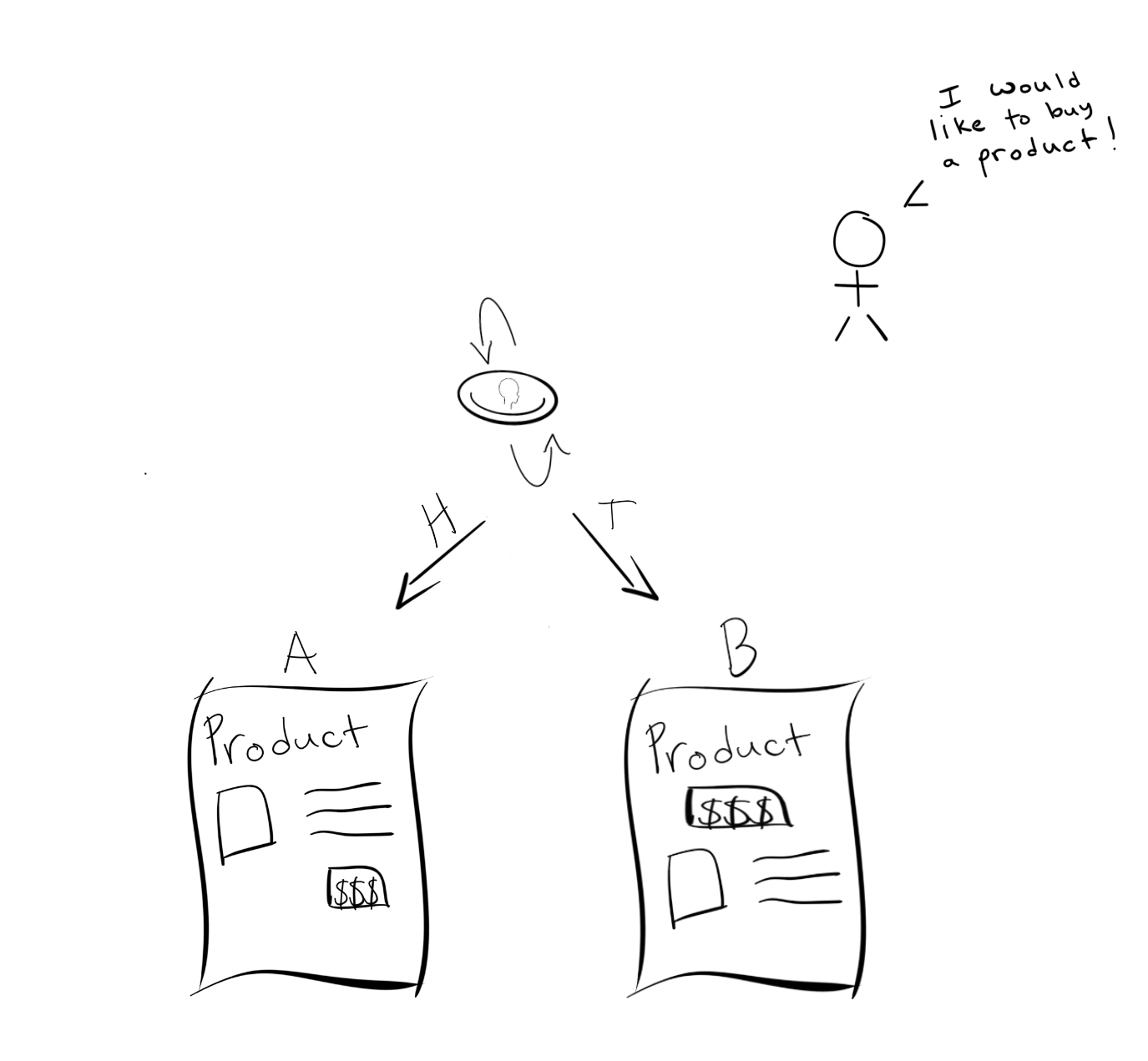
It starts with naive A/B testing then moves to Thompson sampling as a solution to Multi-Armed Bandit problems which are significantly more efficient and only takes a few lines of extra code.
Chapter 3 talks about how a man keeping track of his personal health markers detected colon cancer and was able to get life saving treatment just in time. It gives a good example of how to reason about yourself vs the popluation.
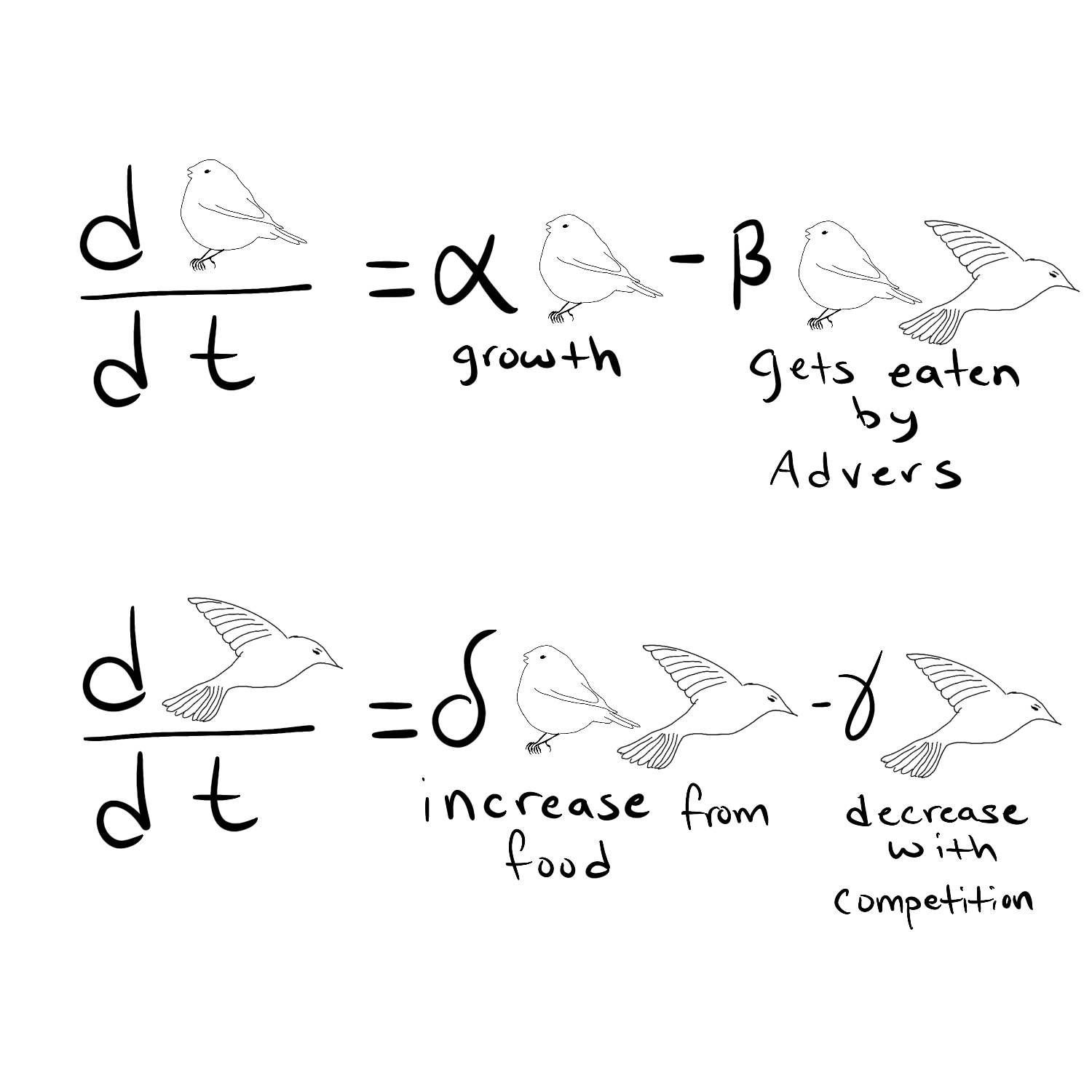
Further on I analyze our dog's potty habits, weight loss using differential equations, and how you can figure out who is carrying your phone just using on-board accelerometer data.
The book has fun illustrations and nice color coded explanations for equations

I've gotten some nice feedback so far, with people saying things like "This is the book I wish I had written", or "I literally have 3 new ideas of how I'm going to use my daily data". Plus, my Mom liked it, so that has to count for something.
At the end of the day, I wrote this book to inspire and encourage people to be aware of their lives, be mindful of what is happening around them, and take control with the techniques often used in data science.
If any of this sounds interesting, you're welcome to buy a copy for yourself. I tried to make the PDF version affordable so it is accessible to everyone.
Buy Paperback on Amazon ($17.49) (kindle version coming soon)Buy PDF/EPUB on Gumroad ($7.99)
2022 update: Everyday Data Science is now an interactive course!
Since I published the book, I've been working with Jim Fisher on a new kind of interactive course. We're transforming the book into a kind of choose-your-own-adventure, except you'll learn Thompson sampling, differential equations, and Bayesian-optimal pricing!
You can get the course on TigYog, or try the first chapter!
Thanks for reading! Feel free to follow me on twitter or Subscribe for email updates
Bonus Content:
I used the Tufte-Book Latex template, Procreate on my iPad for figures, and Kindle Direct Publishing for the physical copy.
I paid a professional editor (but unfortunately there are still a few nice typos) and so far they have made the most from this project.
I want to thank my lovely colleagues who encouraged me and have supported me. And also, I want to thank my Wife for letting me spend 150 extra hours at my computer.